




We understand that in a two-dimensional plane, we have two axes - the X and Y. When two points are placed on the plane, they form a vector, and the distance between these points can be measured. This principle can be extended to any number of dimensions (n-dimensional space). Vectors help us find the difference or relationship between two or more points in multi-dimensional spaces.
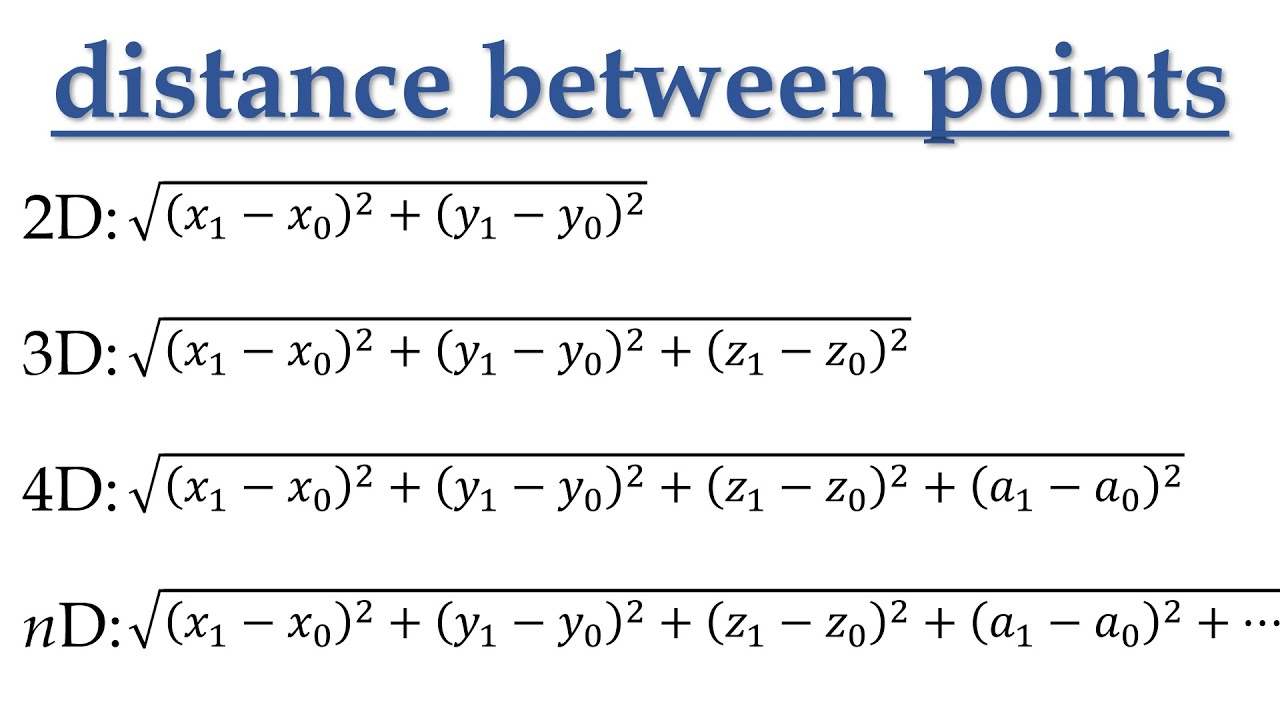
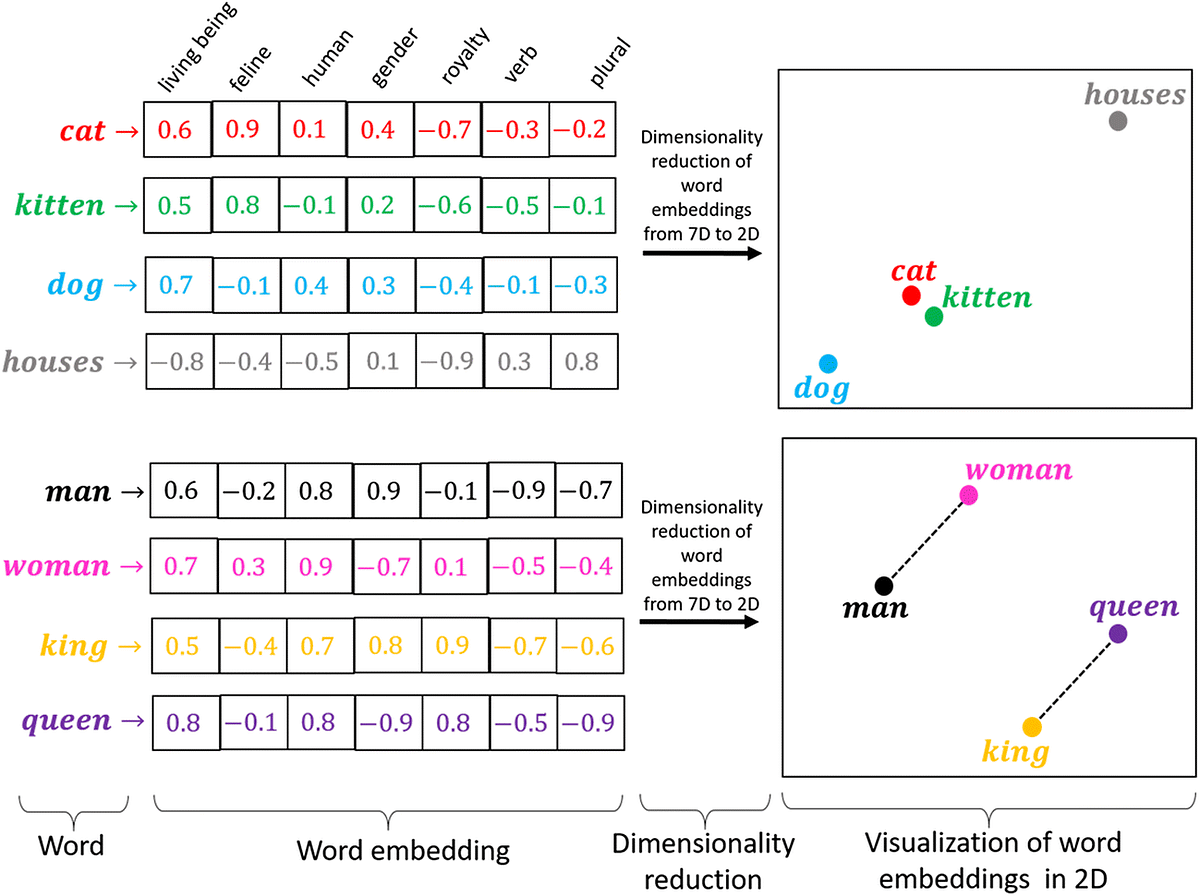
Vector embedding is a technique used in natural language processing (NLP) to represent words, phrases, or entire documents as vectors of numbers.
Let's say we have a sentence "The cat sat on the mat". We can represent each word in the sentence as a vector of numbers using a pre-trained embedding model, such as Word2Vec or GloVe. For example, the vector representation for "cat" might be [0.2, -0.3, 0.8], and the vector representation for "sat" might be [-0.1, 0.5, 0.6].
By concatenating these vectors together, we can create a vector embedding for the entire sentence. So the vector embedding for "The cat sat on the mat" might be:
[0.2, -0.3, 0.8, -0.1, 0.5, 0.6, 0.3, -0.7, 0.4, 0.2, -0.6, 0.1]
This vector representation captures the meaning of the entire sentence in a numerical form, which can be used for a variety of natural languages processing tasks, such as sentiment analysis or machine translation.
It's already in use today
Vector embedding is nothing new, it already exists in a lot of the technologies we use today, including - Google Search, E-commerce platforms, dating apps, etc. We are given relevant products based on previous purchases, relevant information, potential partner matches and more!
How Large Language Models will elevate vector embeddings
Vector embeddings are an underlying part of ChatGPT and other LLMs architecture. They were trained on masses of data, creating numerous vector embeddings. Allowing us to input requests and those chatbots return relevant information.
GPT-4 is introducing support for plugins, which allows users to connect third-party applications to the language model. This is a game-changer because it enables users to extract meaning from various data sources and synthesize it into a vector representation.
For example, let's say you wanted to book a flight to New York:
You have ChatGPT linked to your Google account - it can read your search history, calendar, and everything included in your Google profile.
And you have other plugins needed to book a flight (Payment plans, booking apps, etc.)
You ask ChatGPT: "Book me a flight to New York, I want to get there around 7:00 PM on Sunday and a hotel not too far from 42nd Street, that is mid-range in price"
ChatGPT responds: "Okay, I will proceed to book you a flight to New York City at 3:00 PM, I noticed that based on your search history, you feel claustrophobic at times, so I'm booking you an aisle seat. Also, based on your calendar - you have a meeting earlier that day at 5:00 PM, and you will be in the air during that time - would you like me to cancel that meeting? I also booked a hotel for you within walking distance of 42nd street that's not too expensive"
You respond: "No, don't cancel the meeting, I should be able to answer the call from the plane - book the flight and hotel mentioned. Thank you!"
ChatGPT responds: "Okay, you will receive an email for your receipts."
This is just a simple example, but as you can see, platforms like ChatGPT will be able to map the meaning of otherwise unrelated instances (Google search, music preferences, calendar appointments, etc.) and create meaning between those points and offer relevant suggestions, all being funneled into a chatbot user interface!
Midjourney prompt: Donkey Kong connecting dots on pirate map in dark cave with a torch, Nintendo 64 style --v 5